Admitting the Worker Nodes
After establishing a highly available control plane, the final phase of cluster bootstrapping involves admitting worker nodes. While conceptually simple, this process involves several important considerations for security, automation, and cluster topology.
Worker Node Join Command Generation
The process begins by generating a fresh join command from the first control plane node:
- name: 'Get a kubeadm join command for worker nodes.'
ansible.builtin.command:
cmd: 'kubeadm token create --print-join-command'
changed_when: false
when: 'ansible_hostname == kubernetes.first'
register: 'kubeadm_join_command'
This command:
- Dynamic tokens: Creates a new bootstrap token with 24-hour expiry
- Complete command: Returns fully formed join command with discovery information
- Security: Each bootstrap operation gets a fresh token to minimize exposure
Join Command Structure
The generated join command typically looks like:
kubeadm join 10.4.0.10:6443 \
--token abc123.defghijklmnopqrs \
--discovery-token-ca-cert-hash sha256:1234567890abcdef...
Key components:
- API Server Endpoint: HAProxy load balancer address (
10.4.0.10:6443) - Bootstrap Token: Temporary authentication token for initial cluster access
- CA Certificate Hash: SHA256 hash of cluster CA certificate for secure discovery
Ansible Automation
The join command is distributed and executed across all worker nodes:
- name: 'Set the kubeadm join command fact.'
ansible.builtin.set_fact:
kubeadm_join_command: |
{{ hostvars[kubernetes.first]['kubeadm_join_command'].stdout }} --ignore-preflight-errors=all
- name: 'Join node to Kubernetes control plane.'
ansible.builtin.command:
cmd: "{{ kubeadm_join_command }}"
when: "clean_hostname in groups['k8s_worker']"
changed_when: false
Automation features:
- Fact distribution: Join command shared across all hosts via Ansible facts
- Selective execution: Only runs on nodes in the
k8s_workerinventory group - Preflight error handling:
--ignore-preflight-errors=allallows join despite minor configuration warnings
Worker Node Inventory
The worker nodes are organized in the Ansible inventory under k8s_worker:
Raspberry Pi Workers (8 nodes):
- erenford (10.4.0.14) - Ray head node, ZFS storage
- fenn (10.4.0.15) - Ceph storage node
- gardener (10.4.0.16) - Grafana host, ZFS storage
- harlton (10.4.0.17) - General purpose worker
- inchfield (10.4.0.18) - Loki host, Seaweed storage
- jast (10.4.0.19) - Step-CA host, Seaweed storage
- karstark (10.4.0.20) - Ceph storage node
- lipps (10.4.0.21) - Ceph storage node
GPU Worker (1 node):
- velaryon (10.4.1.10) - x86 node with GPU acceleration
This topology provides:
- Heterogeneous compute: Mix of ARM64 (Pi) and x86_64 (velaryon) architectures
- Specialized workloads: GPU node for ML/AI workloads
- Storage diversity: Nodes optimized for different storage backends (ZFS, Ceph, Seaweed)
Node Registration Process
When a worker node joins the cluster, several automated processes occur:
1. TLS Bootstrap
# kubelet initiates TLS bootstrapping
kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf \
--kubeconfig=/etc/kubernetes/kubelet.conf
This process:
- Uses bootstrap token for initial authentication
- Generates node-specific key pair
- Requests certificate signing from cluster CA
- Receives permanent kubeconfig upon approval
2. Node Labels and Taints
Automatic labels applied:
kubernetes.io/arch=arm64(Pi nodes) orkubernetes.io/arch=amd64(velaryon)kubernetes.io/os=linuxnode.kubernetes.io/instance-type=(based on node hardware)
No default taints: Worker nodes accept all workloads by default, unlike control plane nodes with NoSchedule taints.
3. Container Runtime Integration
Each worker node connects to the local containerd socket:
# kubelet configuration
criSocket: unix:///var/run/containerd/containerd.sock
This ensures:
- Container lifecycle: kubelet manages pod containers via containerd
- Image management: containerd handles container image pulls and storage
- Runtime security: Proper cgroup and namespace isolation
Cluster Topology Verification
After worker node admission, the cluster achieves the desired topology:
Control Plane (3 nodes)
- High availability: Survives single node failure
- Load balanced: All API requests go through HAProxy
- Etcd quorum: 3-node etcd cluster for data consistency
Worker Pool (9 nodes)
- Compute capacity: 8x Raspberry Pi 4B + 1x x86 GPU node
- Workload distribution: Scheduler can place pods across heterogeneous hardware
- Fault tolerance: Workloads can survive multiple worker node failures
Networking Integration
- Pod networking: Calico CNI provides cluster-wide pod connectivity
- Service networking: kube-proxy configures service load balancing
- External access: MetalLB provides LoadBalancer service implementation
Verification Commands
After worker node admission, verify cluster health:
# Check all nodes are Ready
kubectl get nodes -o wide
# Verify kubelet health across cluster
goldentooth command k8s_cluster 'systemctl status kubelet'
# Check pod networking
kubectl get pods -n kube-system -o wide
# Verify resource availability
kubectl top nodes
And voilà! We have a functioning cluster.
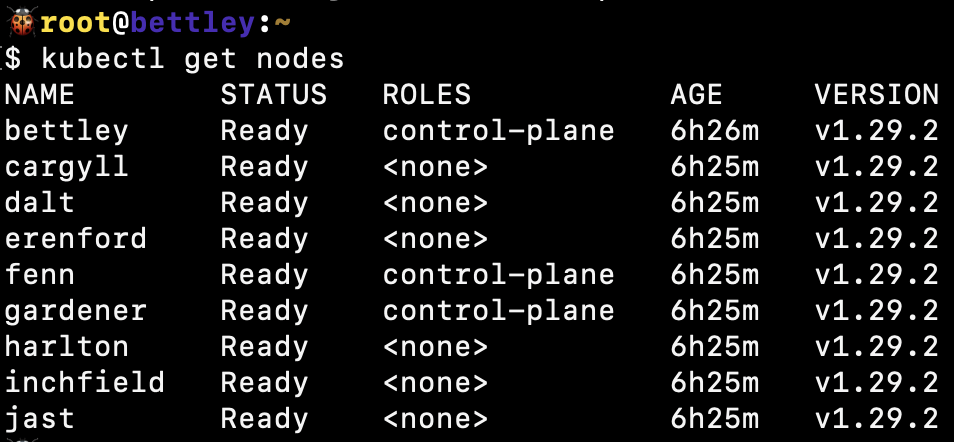
We can also see that the cluster is functioning well from HAProxy's perspective:
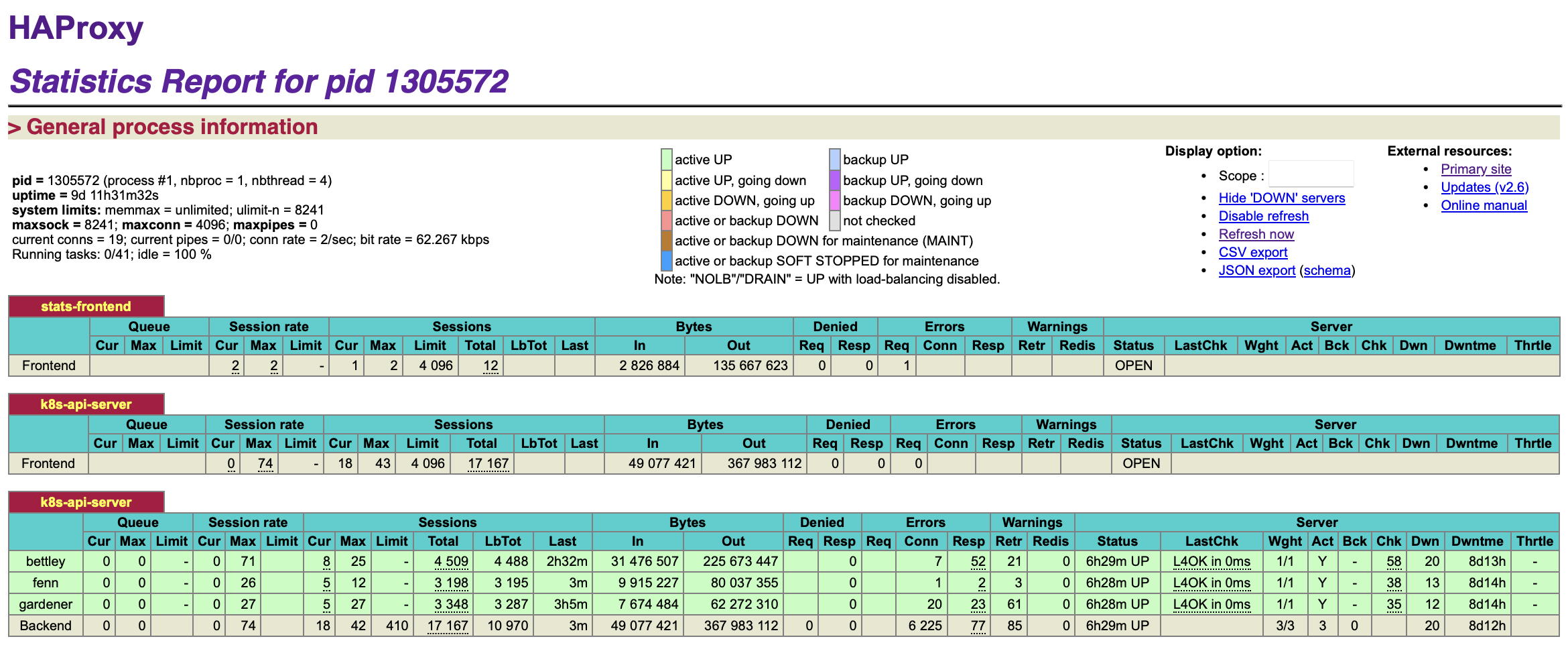
Implementation Details
The complete worker node admission process is automated in the bootstrap_k8s.yaml playbook, which orchestrates:
- Control plane initialization on the first node
- Control plane expansion to remaining master nodes
- Worker node admission across the entire worker pool
- Network configuration with Calico CNI
- Service mesh preparation for later HashiCorp Consul integration
This systematic approach ensures consistent cluster topology and provides a solid foundation for deploying containerized applications and platform services.